728x90
matplotlib 과 statsmodel 패키지를 이용하여 만들어짐
데이터의 통계적인 부분을 살펴볼 때 쉽고 간편하다.
[seaborn import]
import seaborn as sns
sns.set()
pit.rc('font',family='Malgun Gothic')<데이터 숫자를 세는 countplot>
sns.countplot(data=데이터 셋, x='x 축 값');

<4분위 분표>
sns.boxplot(data=데이터 셋, x='x 축 값',y='y축의 값');
(hue 인자로, boxplot 그래프 분리)
sns.boxplot(data=데이터 셋, x='x 축 값',y='y축의 값', hue='값을 나눌 기준');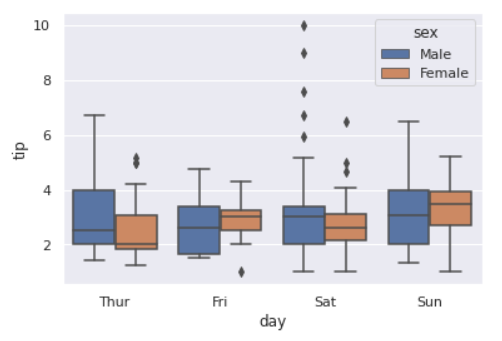
같은 그래프인데 성별로 나누어서 분포 확인 가능하다.
<빈도를 바이올린 모양으로>
sns.violinplot(data=데이터 셋, x='x 축 값',y='y축의 값', hue='값을 나눌 기준');
귀엽..
<두 변수 사이의 관계를 점 찍어 그리기>
sns.scatterplot(data=데이터 셋, x='x 축의 값', y='y 축의 값');
<두 변수 관계를 점과 분포로 보기>
sns.jointplot(data=데이터 셋, x='x 축의 값', y='y 축의 값');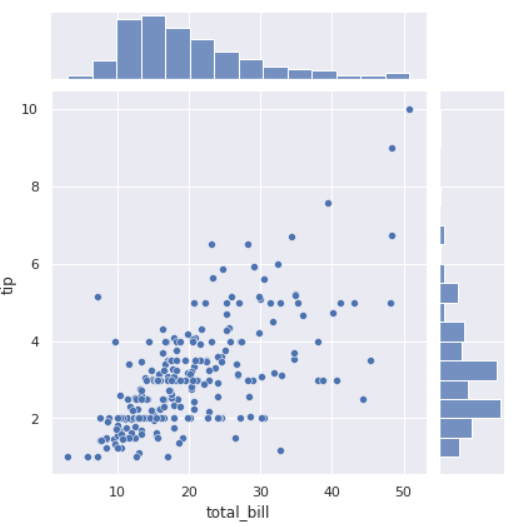
<데이터의 분포를 그리는>
sns.distplot(데이터 셋.데이터, kde=True, rug=True);
kde=확률 분포(선 그래프)
rug=데이터가 실제로 어디에 위치해 있는지 나타냄
728x90
'Machine Learning' 카테고리의 다른 글
| [머신 러닝] Scikit-learn (0) | 2021.09.01 |
|---|---|
| Regression 알고리즘의 성능 평가 지표 (0) | 2021.08.22 |
| [PANDAS] matplotlib으로 그래프 그리기 (0) | 2021.08.15 |
| [PANDAS] 함수 (.concat)(.groupby)(.query) (0) | 2021.08.15 |
| [PANDAS] DataFrame -> CSV 파일로 저장하기 (0) | 2021.08.15 |